就在这最近的两天时间里,资本市场当中最为热闹的一件事情,便是那个有着1.6T参数的V4模型实现了完整的开源。这个运用了MoE架构的旗舰模型,它还和有着285B参数的Flash版本一同,借助2.0协议,将权重以及部署代码全都公开了出来。此消息一经传出,A股算力链几乎是全线呈现出跳涨的态势,然而港股大模型公司那边却呈现出另外一种情形,那就是单日做空数据创下了过去三个月以来的新高。同样都是中国的AI公司,市场给出了全然相反的判决。
同一时刻两种颜色 钱在重新选边
于4月24日上午,V4开源消息得以落地,在A股这边,寒武纪、海光信息以及华为昇腾相关产业链公司的股价,随即应声出现跳涨。买方机构的交易记录表明,在开盘之后的第一个小时之内,算力相关股票的买入量,是前五个交易日日均值的3.2倍。而在港股那边,有两家将于2025年下半年上市的AI公司,其IPO招股书当中都写着“自研基座大模型”,然而在当天,却遭遇了过去三个月之中最高的单日做空量。彭博所做的速评,将此次盘面,与1月27日的“V3时刻”,进行了对比,其区别在于,1月那次呈现的是恐慌式抛售,单日就有6000亿美元蒸发,而此次则是结构性分化。
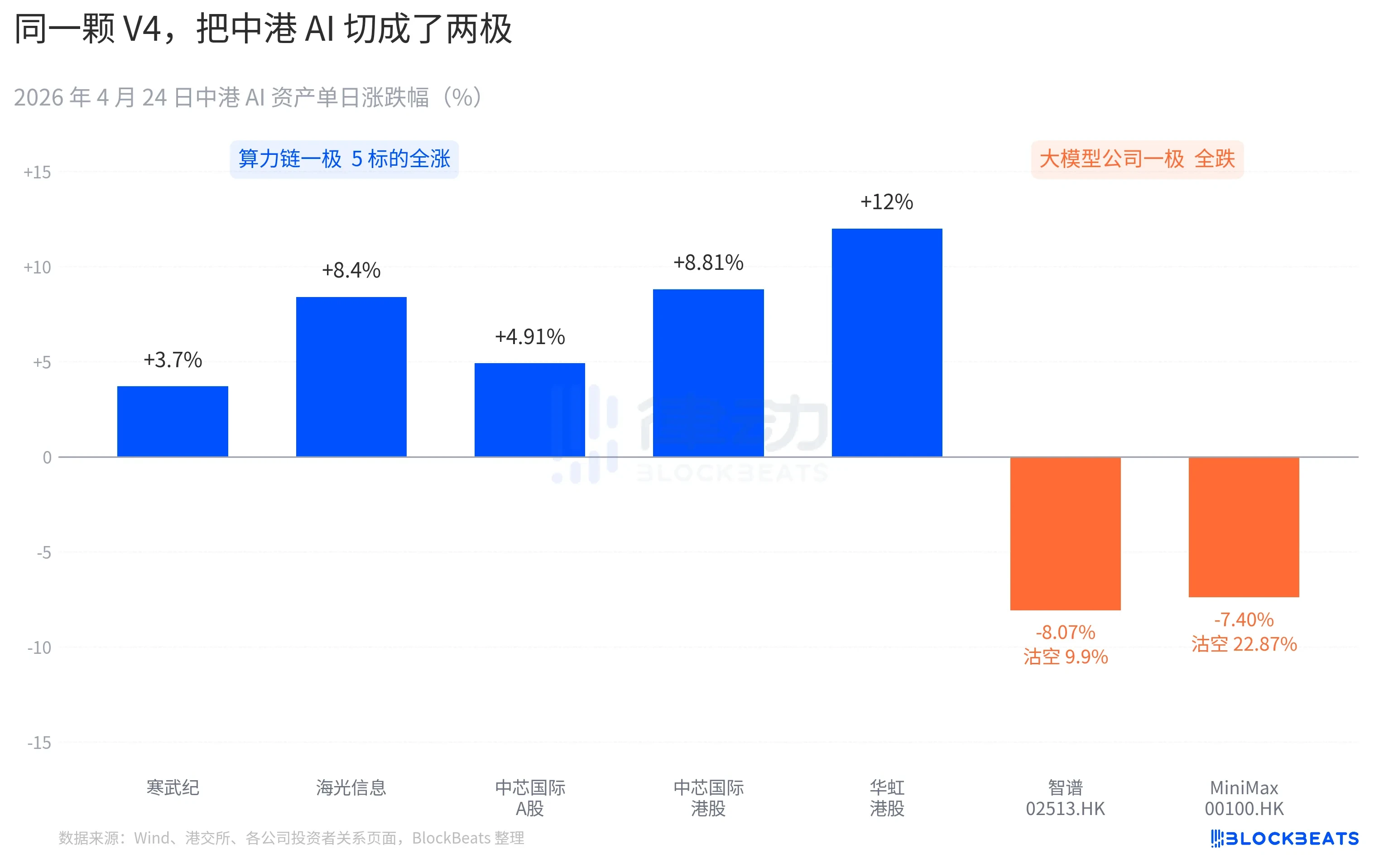
于华尔街的一份买方研究纪要之中,出现了这样一句全新的表述,即“中国AI推理需求开始与北美AI推理需求脱钩” ,这句话的背后是确确实实的数据 ,V4发布之后的24小时之内,北美投向中国AI资产的资金呈现出净流出的状态,为1.2亿美元 ,与此同时,内地资金借助港股通实现了净买入,金额为4.7亿港元 ,三块盘面相互堆叠,这便是市场所书写下的第一份判决书 ,在开源胜出以后,能够进行定价的并非是模型本身了 ,而是模型运行于哪一块卡之上 ,以及安装在哪一条产业链之中 ,钱开始重新进行选边 ,并且选得十分坚决。
30天11个新模型 V4凭什么是点火的那个
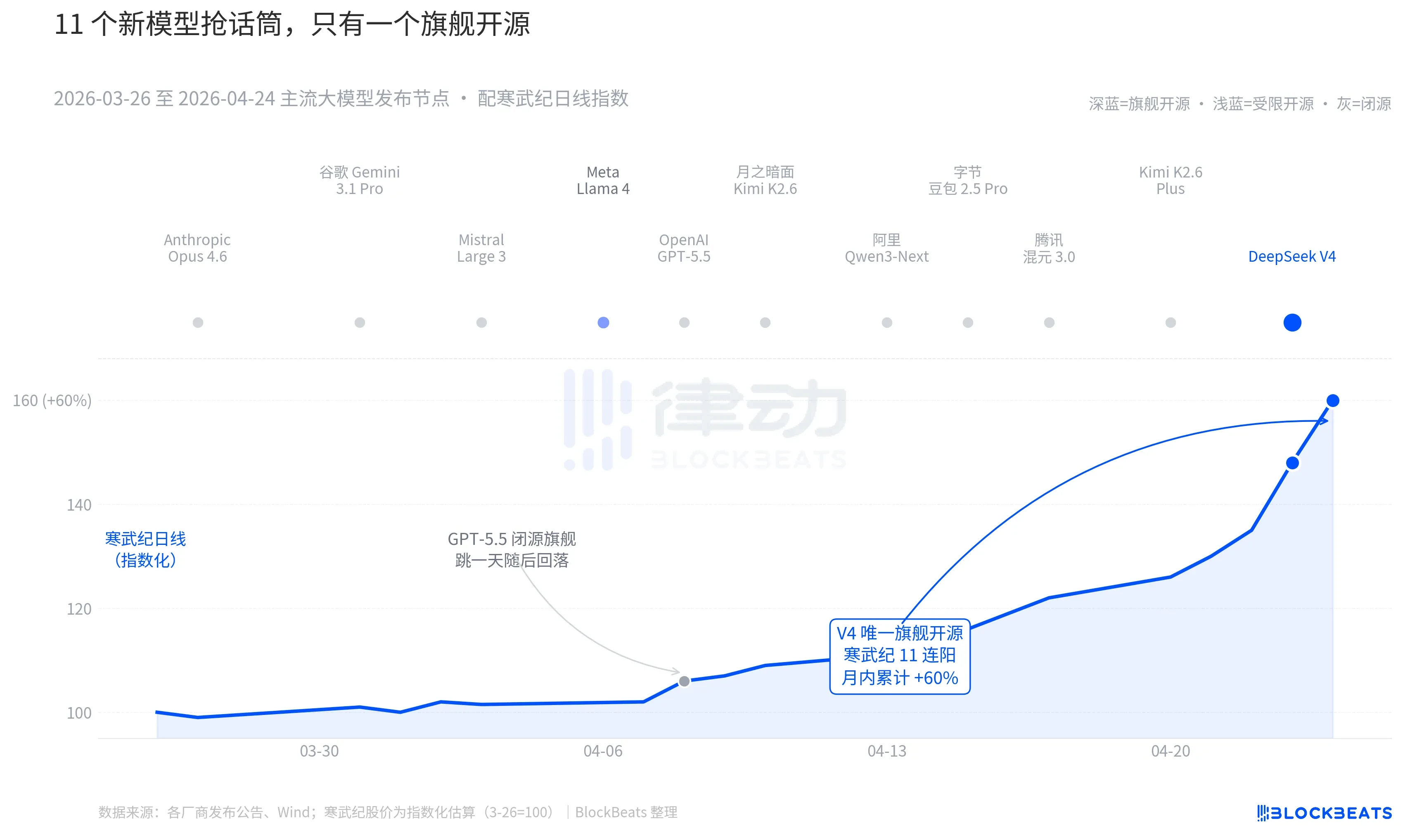
从3月26日起,直至4月24日,全球范围内,至少存在11个,具备显著影响力,的大模型,进行了发布,或者有着重大更新。名单涵盖了所有主要参与者,从OpenAI开始,进而到谷歌,再到Anthropic,就连基金经理都声明来不及读完发布稿。然而,翻阅一遍这30天的中港AI资产K线,可以在盘面上留下持续踪迹的,仅有一个名字。4月8日,GPT – 5.5促使英伟达单日上涨4.2%,但次日便见顶回落。而V4在4月23日至24日,带动中港算力链出现连续跳涨。
11个模型于LMSYS排行榜上所呈现的差距,多数情形下未超出50分,处于“同一段位”的狭窄范围之内。前10个模型当中仅有Llama 4是开源的,然而其权重协议附带了一长串的商用限制条款,欧美开发者社区给予的评价较为冷淡,上线第三天便跌出前十。V4的协议是2.0,其权重没有门槛限制,商用不存在约束,推理代码同步进行了释出。这是过去半年里首个令闭源阵营在性能、价格、开放度这三个维度同时面临压力的旗舰开源模型。一位在国内大型基金领域任职的经理,于路演期间表示,在V4这个时间节点之前,我们针对开源大模型的估值预留了一定程度的折扣,而在V4之后,此折扣开始朝着相反方向收取了。
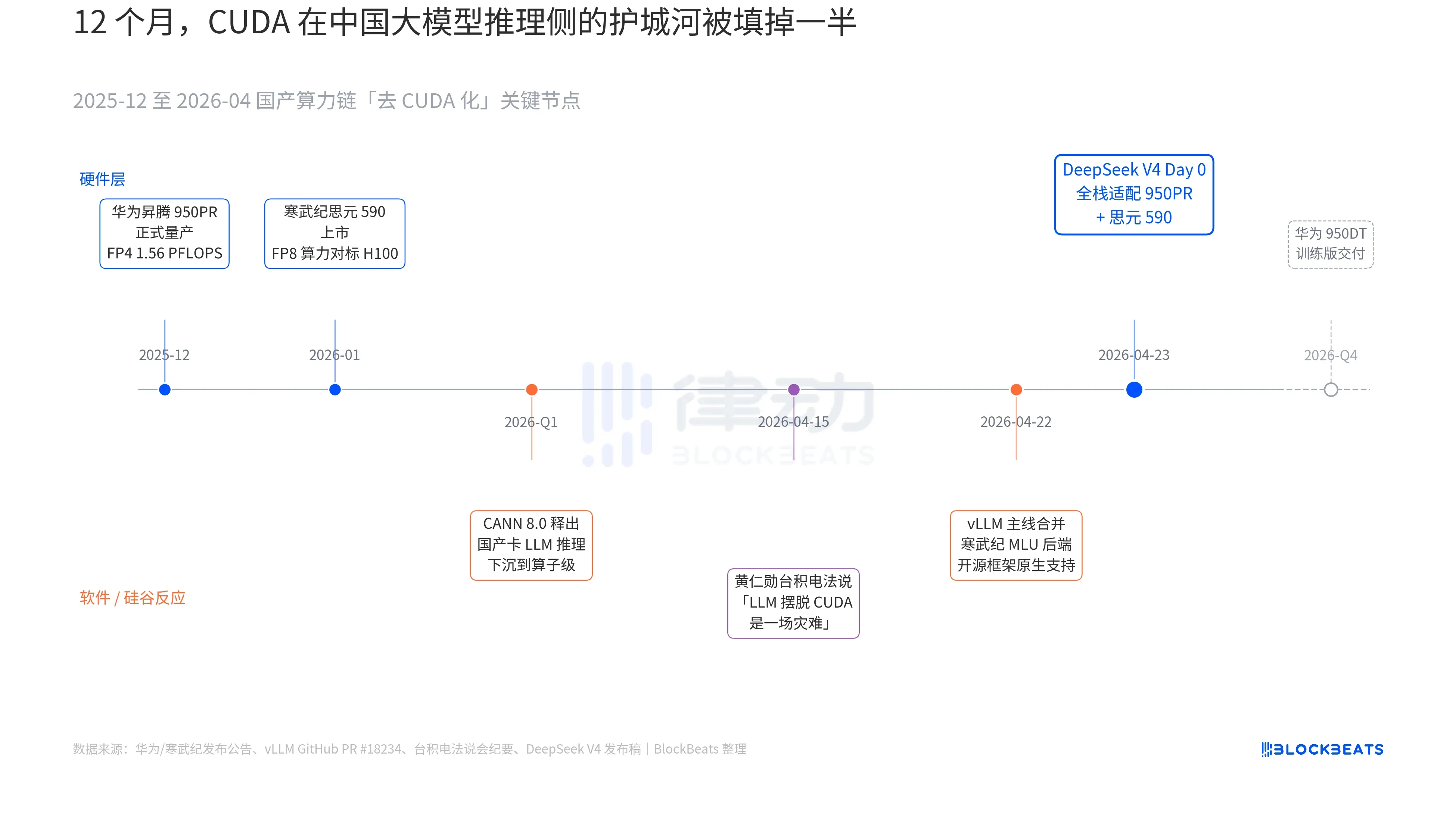
一行从未出现过的字 改变了算力格局
在V4发布稿当中,存在着一行字,这行字先前从来都未曾在任何中国大模型的官方文档里出现过 ,其文字内容为:“Day 0全栈适配寒武纪思元590与华为昇腾950PR,部署代码同步开源。”那么这一行字究竟有着多大的分量呢 ,实际上要把过去12个月里三条平行展开的暗线连接到一起才能够看得明白。华为昇腾950PR在2025年12月正式实现量产 ,其FP4算力达到了1.56P ,HBM容量为112GB ,这是国产AI芯片首次在硬指标方面对标英伟达B系列。
配备对应CANN 8.0软件栈,将LLM推理框架优化下沉至算子一级。已公开的Benchmark表明,V4于昇腾超节点(8卡950PR)上的端到端推理延迟相较于同等规模的H100集群而言低了35%。寒武纪思元590的数据更为突出,单芯片FP8算力可与H100对标,且售价还不到一半。4月22日,vLLM主线合并了寒武纪MLU后端PR,开源推理框架实现了首次原生支持非英伟达的国产GPU。这表明,V4的部署情况发生了变化,不仅仅局限于只能在某一家国产卡上运行,现在变成了能够在多家国产卡之间进行选择,如此一来,生态对于单点供应商的那种依赖状态,就被打破了。
黄仁勋担心的事 正在变成现实
4月15日,于台积电的法说会上,黄仁勋遭分析师追问中国国产算力的进展情况, 他言辞冷峻且具体地表示:“若他们真能使LLM摆脱CUDA,对我们而言会是一场灾难。” 然而在4月24日上午之后,此事首次出现了能被资本市场定价的具体数据, 单卡吞吐、端到端推理延迟、推理成本、可商用的部署代码,这些数字悄然无迹地将这场漫长的话术战推至质变的门槛范围之内。
有这样一家公司,它之前被归为“国产GPU概念股”类别,在V4发布之后,又重新受券商涵盖,那时标签被改成了“V4推理基础设施供应商”。每一个在国产异腾上运行的V4 token,都意味着那么一些原本会流向英伟达以及台积电那儿的产能,被部分截留在了珠江三角洲地段。华为的路线图已然清晰,950DT训练版计划在2026年第四季度予以交付,与之对应的目标是“V5或同等水平Model在1万卡集群上的全栈训练”。倘若这条道路能够实现畅通无阻地通行的话,那么针对中国大模型在训练这一方面而言的CUDA的相关防护设施,将会从原本所具备的“必要”这一等级,下降转变为处于“可选”的层面。
开源旗舰落地 产业链开始重新估值
并非模型本身是V4开源的直接受益者,而是能使它运行起来的整条国产算力链,是受益者。从昇腾950PR的算力板卡开始说起,到寒武纪的MLU后端,再到海光DCU的ROCm适配,每一个层面都有上市公司在接过这波红利。在券商于V4发布之后连夜更新的研报当中,把国产算力公司的目标价平均提高了18%至25%。涨幅最大的并非芯片设计公司,而是封装和测试环节的两家厂商,原因在于V4的大规模推理部署直接带动了先进封装的订单。
原本这波重估的那个逻辑是特别直白的,以往市场针对国产算力所给出的估值,是建立在“替代”这个逻辑基础之上存在并且假设国产卡仅仅能够获取英伟达所逸出来的那些低端订单而已,然而V4证实了一件事情,那就是国产卡能够在同等水平甚至更低的推理延迟状况之下运行旗舰级开源模型,这并非替代,而是并行,有一位半导体分析师曾经通过电话会议予以表述称,我们当下针对国产算力所采用的模型,已经不再是“国产替代”这一单纯估值体系,而是“全球推理基础设施”这样的体系,两个体系之间所存在的价差,大概还有30%。
从训练到推理 生态拐点已经出现
V4 最大的意义并非在于它相较于 GPT – 5.5 高出多少,而是在于它使得开源模型首次在“可部署性”方面超越了闭源模型的情况。闭源模型的推理只能通过官方 API 进行,其价格、延迟以及数据安全均不由用户掌控。然而,V4 给予了用户全方位的控制权:代码掌握在自己手中,权重掌握在自己手中,就连在哪块卡上运行也由自己来决定。对于企业用户而言,这意味着从“租模型”转变为“拥有模型”的重大质变。
在过去的两年当中,始终以来,硅谷那边都持续不断地在围绕着开源究竟能不能够追赶上闭源这一问题展开争论。然而,由于V4推出了一款月活预估能够迅速冲到9000万的开源旗舰产品,从而使得这场争论被按下了暂停键。更为关键之所在的是,它充分地证明了中国AI产业链所具备的协同能力,具体来看,就是模型团队、芯片厂商、框架开发者以及云服务商,在同一个特定的时间点成功地完成了适配以及交付这一系列工作。这并非是那种单点突破的情况,而是意味着一种生态级别的胜利。当开源模型能够在国产卡上以更低的延迟以及更低的成本去完成推理操作的时候,全球AI推理的版图于是就逐步或正在开始重新绘制了。
仅仅才过了24小时,在V4开源之后,市场之上就已经有人在询问下一个问题了,那就是:当V5出现之际,国产训练卡能够承接得住吗?华为950DT的交付时间规划表是2026年第四季度,留给双方的时间均不足一年。你试问是否觉得在一年之内,国产AI芯片能够在训练这一侧面追上英伟达的CUDA生态呢?欢迎于评论区域留下你的观点看法,同时也热忱欢迎予以点赞转发,从而让更多的人能够目睹到中国AI产业链的真实发展进程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。