我们长久以来都认定,AI模型越大便越具聪慧,然而浙江大学开展的一项全新研究却给出了全然相反的答案,当模型参数急剧增加十几倍之后,识别猫狗这类具体事物的能力的确有所提升,可是理解“生物”与“非生物”这种抽象概念的能力反倒出现了倒退。
大模型的规模神话正在被打破
以往的几年时间里,AI领域的主要做法便是将模型做得愈发庞大,从几千万的参数增长至几百亿的参数,众人坚信规模能够化解所有问题,这种观念源自一种直觉,即参数数量越多,模型就会越趋近于人脑的思考模式,科技企业为此投入了数额巨大的资金,堆砌起了成千上万块显卡。
然而,由浙大团队发表的论文,是在2026年4月1日发布的,此论文直接对这个观点发起了挑战。他们有所发现,当模型参数从2206万增长到3.0437亿之后,针对具体概念任务而言,其准确率从74.94%上升到了85.87%,可是,对于抽象概念任务来说,却反倒从54.37%下降到了52.82%。这表明,模型正变得愈发“死板”。
人脑和模型的分岔路口
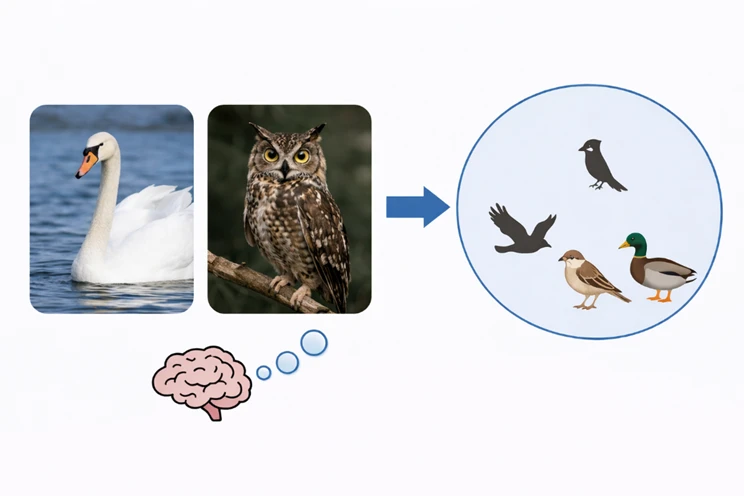
当我们看到天鹅以及猫头鹰之时,人脑处理信息的方式颇为特别,尽管它们在外观上呈现出全然不同的模样,然而大脑会自然而然地将它们统统归拢到“鸟类”这一范畴之内。进一步而言,鸟和马又能够被放置进“动物”这个更为宽泛的类别之中。并且,这种具备分层分类特性的能力是自动进行发生的。
你看到一只从未见过的动物时,会本能去想,它跟什么存在相似之处,大概归属哪种类别,这便是抽象概念发挥作用,人脑无需见过所有事物,便能凭借已有的分类体系迅速判断新事物,这种能力使得人类的学习效率远超机器。
模型为什么越学越不会抽象
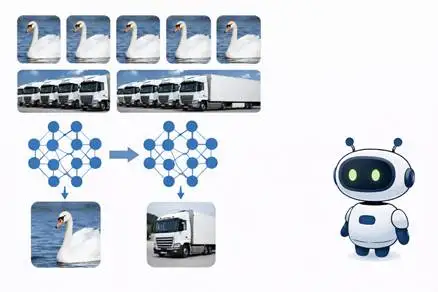
模型形成分类的方式全然不一样,它所依赖的是统计规律,要是某个物体在训练数据里频繁出现,模型便能将其识别出来,然而若要使其理解“鸟类”这个概念,它得抓住天鹅、猫头鹰、麻雀之间的相同点,接着把这些相同点归为同一类。
这个进程于现存模型而言极为艰难,参数持续增大之际,模型会將更为多的注意力置于具体对象的细节方面,反倒忽略了更高层级的共性,这便阐释了为何抽象概念任务的表现会降低,即模型正变得愈发善于辨认具体事物,却愈发不擅于归纳总结。
浙大团队的另类解法
针对这个问题,浙大团队并未选取去持续堆叠参数。他们采用的方案乃是借助人脑的活动信号来教导模型。具体的操作办法是:让志愿者观看图片,与此同时记录他们的大脑活动数据,随后把这些数据输入至模型,以使模型仿造人脑的分类方式。
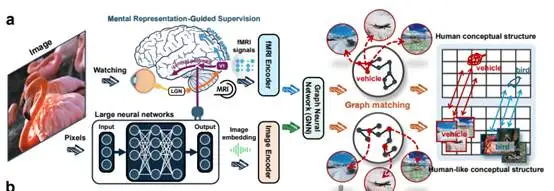
实验采用了150个训练类别,以及50个测试类别。其结果表明,历经这种训练之后,模型跟大脑活动模式之间的距离持续呈现出缩小的态势。更为关键的是,这种改善在训练过的类别这一方面出现,而且在没训练过的类别这一方面也出现,这表明模型所学到的并非是死记硬背。
规模之外的进化新方向
在仅给出极少示例的情形下,要求模型去区分生物与非生物这种抽象概念,经过脑信号训练后的模型,平均提升幅度为20.5%,这个成绩超越了参数量大得多的对照模型,团队还进行了31组额外测试,各类模型均出现了接近一成的稳定提升。
这表明,AI的进化趋向或许遭到了我们的误判。以往,众人仅仅聚焦于训练时期的规模扩充,然而,在模型训练完结之后,其于现实世界里的持续演变同样具有重要意义。AI在直面真实反馈之际怎样进行自我调适,怎样于持续不断的预测与验证当中优化自身架构,这大概才是更为关键的难题。
让AI真正学会思考
浙江大学所开展的研究,与一些人工智能实验室当下正着力探索的方向,达成了高度的契合:致力于使人工智能不再仅仅是一台只会解答题目的机械装置,而是能够拥有真正意义上的思考能力。达成这一目标,需要对当前单纯一味追求参数规模的行为方式作出改变,将着重关注的重点重新移回到认知结构自身。
人体大脑的高阶视觉区域,会自然而然地划分出生物与非生物这样的大类,然而模型当前却没办法做到这一点。若要使AI拥有真正的抽象理解以及迁移能力,那就需要让其内部结构更趋近于人体大脑的分类方式。这大概才是通向通用人工智能的真正途径。
瞅见这儿,我要问你个事儿:要是你手机里有个大模型助手,你是期望它识别物体的精准度提升百分之五,还是期望它领会诸如“公平”与“正义”这般抽象概念的本事提升百分之五呢?欢迎于评论区分享你的见解,也别忘记给这篇文章点赞以及转发哟。
© 版权声明
文章版权归作者所有,未经允许请勿转载。