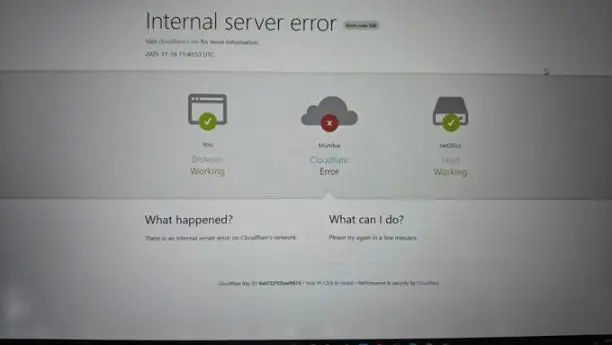
全球焦点再次被网络服务中断占据,一次技术故障看似平常,却致使数百万用户陷入一片混乱之中,。
故障影响范围

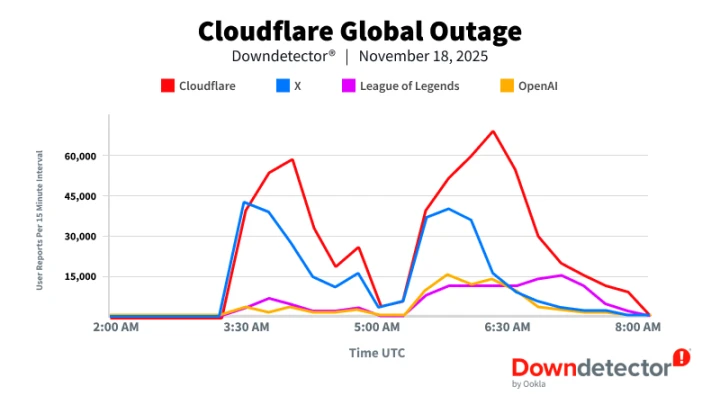
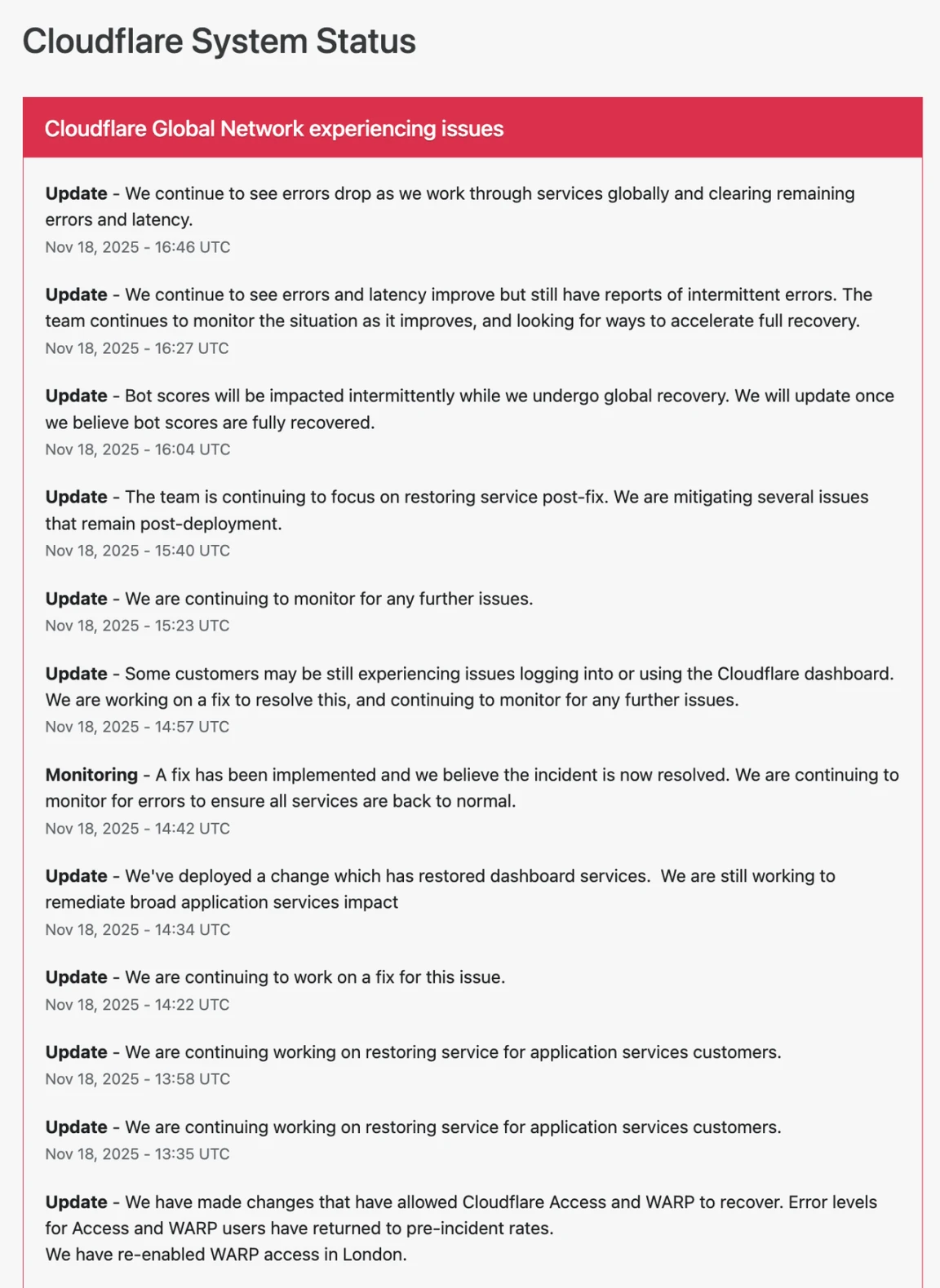
此次事件所涉及的范围,远远超过某一个单独的平台,依据公开的数据,在全球范围内,超过210万份存在问题的报告,集中地大量出现,这些报告覆盖了电子商务、社交媒体以及金融服务等多个重要的关键领域,在美国东海岸处于清晨的那个时段,众多的企业忽然之间就没办法处理线上交易了,在欧洲地区,用户遭遇到了登录方面的障碍,在亚洲部分区域,视频流媒体服务出现了持续不断的卡顿现象。

在故障持续的那段时期,在线零售商的销售额显著下滑,部分餐饮配送平台的订单处理延迟超出两小时。社交媒体上投诉急剧增多,话题标签在推文平台快速传播,用户都在分享各自碰到的服务异常状况。
事故根本原因
技术团队最后确定,事故起因是一个自动生成的安全配置文件,这个文件本来是用来筛选恶意网络流量的,可是因为条目数量超过了设计预期数量,直接致使处理系统因为过载而崩溃,这样的配置异常造成正常用户请求没办法通过安全验证环节。
2019年时,类似配置问题曾致使服务中断,那时因软件资源分配不均衡,致使全球数以千计的网站离线大约三十分钟。此次事件里,故障从触发直至完全修复总共耗费将近四小时,远远超过日常维护的平均用时。
修复过程分析
在发现问题之后,工程师即刻启动了紧急预案,他们先是隔离了故障组件,接着部署了经过优化的配置文件版本,整个修复过程涵盖多个验证阶段,以此确保新配置不会引发连锁反应。
于美国东部时间中午十二点十五分之际,核心服务渐渐恢复至正常运行状态。然而,鉴于系统缓存刷新所需时间之故,部分用户在后续两小时之内依旧报告存在访问延迟情况。技术团队始终持续监控各项指标直至当晚,以此确保所有区域服务全然稳定 。
行业连锁反应
此次事件再度突显现代数字生态之脆弱性,从航空公司订票系统而言,到银行支付网关,众多关键服务同时呈现异常状况,去年所发生的类似事故,曾致使数千架次航班延误,政府机构办公系统陷入瘫痪,医疗机构的在线预约系统被迫终止服务 。
从数字化程度相对较高的国家来说,此类基础设施出现故障后,所造成的经济损失,每分钟能够达到数十万美元之多。中小型企业,因为缺少备用方案,总会成为受影响最为严重的群体,它们的日常运营,对那些云服务提供商存在着高度的依赖 。
系统脆弱本质
已成为行业隐忧的是,互联网基础设施呈现出高度集中化的状态。当下,全球范围内大部分的网络流量,是由少数几家云服务商予以承载的。这样的一种架构,虽说提升了效率,然而也创造出了单点故障的风险。一旦核心服务出现问题,那么依赖这些服务的各类应用,就会如多米诺骨牌那样接连失效。
网络安全方面的专家明确提点,好多机构出于把成本降低的目的,把所有的服务都放置于同一个平台之上,并且缺少有效的备用应对方案。这样的一种策略在平常的运营期间看起来好像是高效的,然而一旦碰到系统层面的故障,就会导致全面性的瘫痪情况发生。
未来预防措施
处于行业之中领先地位的企业着手重新对其架构设计展开评估,部分公司当下正在施行多云策略,把关键服务分散于不同供应商的平台当中,技术团队与此同时也在努力开发更为灵活的流量管理机制,以此来避免由于单一组件故障致使整个系统出现崩溃的情况。
对于监控系统,服务提供商作出承诺,要进行改进,力争在异常开始发生的初期阶段就能够及时地实施干预。与此同时,他们也正在对建立行业协作机制这件事展开思考,通过实现共享最佳实践来达成提升整体基础设施稳定性的目的。
这一回的事件,有没有致使您再次进行思索,关于对数字服务的依赖程度呢?欢迎于评论区域分享您的经历,要是认为本文具备价值,请予以点赞支持,并且分享给更多的友人。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


